About a year ago I wrote GPU Texture Compression Everywhere, a post in which, among other things, I lamented that Metal did not have support for writing to compressed textures.
Unlike Vulkan or D3D12, Metal doesn’t support resource casting. There’s no way to write to a compressed texture through an uncompressed view. The only way we can do that is by using a blit operation, so we need to output our results to a temporary buffer and then copy the contents of the buffer to the texture. This requires a temporary memory allocation that needs to be managed, and if the buffer is reused for multiple uploads, hazard tracking may add some synchronization overhead.
I requested support for this feature to Apple when I started working on Spark, more than 3 years ago. Since then not much progress has been made, and support is still not available, so I decided it was time to take matters into my own hands.
The workaround I came up with is to emulate resource casting by using a Metal heap to allocate the two resources at the same memory location:
// Determine block compressed texture size:
MTLTextureDescriptor* bc_desc = [MTLTextureDescriptor
texture2DDescriptorWithPixelFormat:MTLPixelFormatBC7_RGBAUnorm
width:input.w height:input.h mipmapped:false];
bc_desc.storageMode = MTLStorageModePrivate;
bc_desc.usage = MTLTextureUsageShaderRead;
MTLSizeAndAlign sa = [device heapTextureSizeAndAlignWithDescriptor:bc_desc];
// Allocate heap:
MTLHeapDescriptor* hd = [[MTLHeapDescriptor alloc] init];
hd.size = sa.size;
hd.storageMode = MTLStorageModePrivate;
hd.hazardTrackingMode = MTLHazardTrackingModeUntracked;
hd.type = MTLHeapTypePlacement;
id<MTLHeap> heap = [device newHeapWithDescriptor:hd];
// Allocate texture and buffer at the same location:
id<MTLTexture> bc_tex = [heap newTextureWithDescriptor:bc_desc offset:0];
id<MTLBuffer> bc_buf = [heap newBufferWithLength:sa.size
options:MTLResourceStorageModePrivate offset:0];We then write to the buffer and read from the texture. With fences to synchronize access, we can ensure writes are visible before sampling:
// Invoke Spark kernel
id enc = [cb computeCommandEncoder];
[enc useResource:bc_buf usage:MTLResourceUsageWrite];
// … dispatch spark kernel …
[enc updateFence:fence];
[enc endEncoding];
// Sample the aliased texture from compute or graphics.
[enc2 waitForFence:fence];
[enc2 useResource:bc_tex usage:MTLResourceUsageSample];
// … dispatch that samples bc_tex …
[enc2 endEncoding];However, for this to work the codec needs to read the input texture and write to the output buffer taking texture swizzling into account. For an overview of how texture tiling works, I recommend Fabian’s post: Texture Tiling and Swizzling
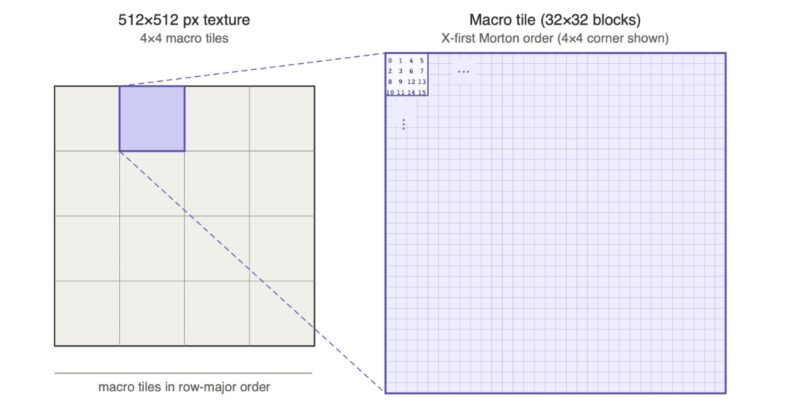
To determine the tiling order on Apple silicon, I wrote blocks with increasing color values and read back the buffer to observe the storage order. On the M4 (the machine I’m writing this on), the GPU uses the following approach for BC blocks: The texture is divided into macro tiles (32×32 blocks, or equivalently 128×128 pixels) arranged in row-major order. Within each macro tile, blocks are stored in X-first Morton order.
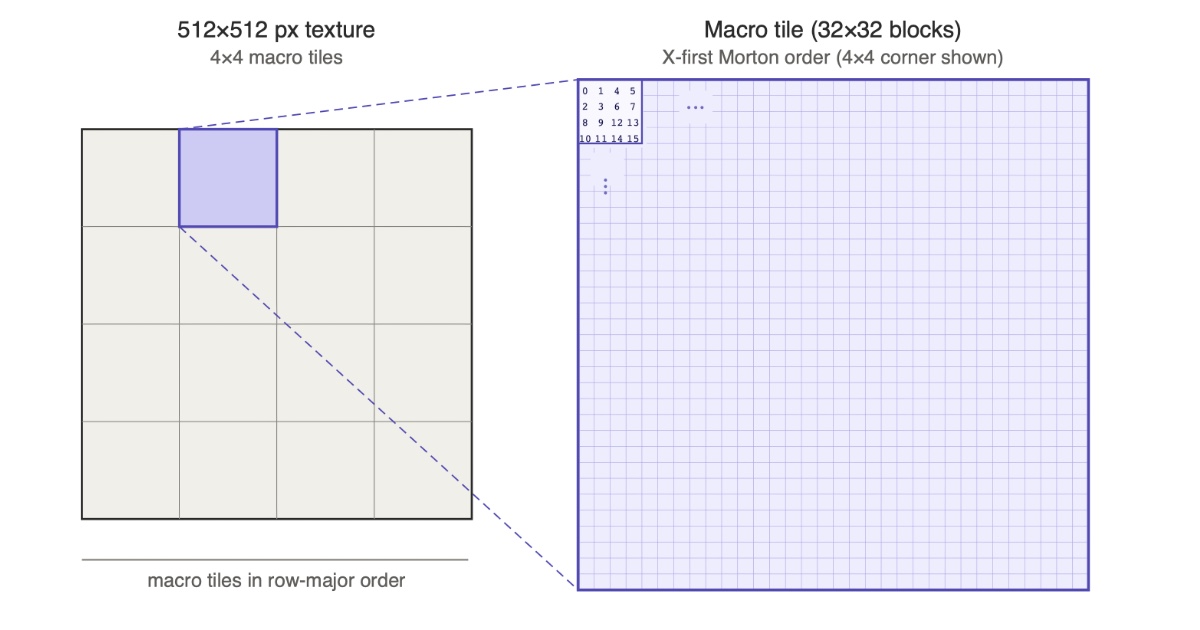
There are two ways to write a texture encoder that produces swizzled output: Read 4×4 pixel blocks linearly and scatter writes, or gather reads and write compressed blocks linearly. For each approach need to either compute the linear address for a 2D coordinate, or the 2D coordinate of a linear address.
For that we need to compute Morton codes efficiently, and Fabian also has an article covering that subject: Decoding Morton Codes
In our case we only need to interleave the lower 5 bits of each coordinate to index within a macro tile. We can do this efficiently by packing both coordinates into a single word, x in bits 0–4 and y in bits 16–20, and then spreading or compacting both halves in parallel through the same shift-and-mask chain. This lets us encode or decode both coordinates in a single pass:
// X-first Morton encode two 5-bit coordinates packed in one word.
// Pack x in bits 0..4 and y in bits 16..20, spread both halves in parallel
// through the same shift-mask chain, then merge the two 10-bit results.
inline uint morton10(uint x, uint y) {
uint v = (x & 0x1Fu) | ((y & 0x1Fu) << 16);
v = (v | (v << 4)) & 0x0F0F0F0Fu;
v = (v | (v << 2)) & 0x33333333u;
v = (v | (v << 1)) & 0x55555555u;
v &= 0x03FF03FFu;
return (v | (v >> 15)) & 0x3FFu;
}
// Inverse: extract (x, y) from a 10-bit X-first Morton index.
// Place even bits (x) in bits 0..4 and odd bits (y) in bits 16..20,
// then compact both halves in parallel.
inline uint2 morton10_inv(uint m) {
uint v = (m & 0x155u) | ((m & 0x2AAu) << 15);
v = (v | (v >> 1)) & 0x33333333u;
v = (v | (v >> 2)) & 0x0F0F0F0Fu;
v = (v | (v >> 4)) & 0x001F001Fu;
return uint2(v & 0x1Fu, (v >> 16) & 0x1Fu);
}For the version that writes blocks in swizzled order, we use a 2D kernel. Threads form a 2D grid over the (bx, by) block coordinates. Each thread reads its 4×4 input block in scan order and writes the encoded BC7 block at the swizzled buffer offset.
constant uint MT = 32u; // macro-tile size in blocks
// (bx, by) to linear slot index in the heap buffer.
// `bw` is the number of blocks across the texture.
inline uint bc_block_slot(uint bx, uint by, uint bw) {
uint mt_grid_w = (bw + MT - 1u) / MT;
return ((by >> 5) * mt_grid_w + (bx >> 5)) * MT * MT + morton10(bx, by);
}
kernel void encode_writes_swizzled(
texture2d<half, access::read> src [[texture(0)]],
device uint4* output_blocks [[buffer(1)]],
ushort2 gid [[thread_position_in_grid]])
{
uint bw = (src.get_width() + 3u) / 4u;
uint bh = (src.get_height() + 3u) / 4u;
if (gid.x >= bw || gid.y >= bh) return;
half3 rgb[16];
read_rgb_block(src, gid * 4, rgb);
uint slot = bc_block_slot(uint(gid.x), uint(gid.y), bw);
output_blocks[slot] = spark_encode_bc7_rgb(rgb, quality);
}For the version that reads blocks in swizzled order, we use a 1D kernel. Threads form a 1D grid over the linear slot indices in the buffer. Each thread reverses the swizzle to find the (bx, by) block coordinates it owns, reads that 4×4 block from the input texture, then writes the encoded block at its own linear slot.
// Linear slot to (bx, by). Inverse of bc_block_slot.
inline uint2 bc_slot_to_block(uint slot, uint bw) {
uint mt_grid_w = (bw + MT - 1u) / MT;
uint mt_index = slot / (MT * MT); // 1024 blocks per macro-tile
uint2 local = morton10_inv(slot - mt_index * MT * MT);
uint mt_y = mt_index / mt_grid_w;
uint mt_x = mt_index - mt_y * mt_grid_w;
return uint2(mt_x * MT + local.x, mt_y * MT + local.y);
}
kernel void encode_reads_swizzled(
texture2d<half, access::read> src [[texture(0)]],
device uint4* output_blocks [[buffer(1)]],
uint tid [[thread_position_in_grid]])
{
uint bw = (src.get_width() + 3u) / 4u;
uint bh = (src.get_height() + 3u) / 4u;
uint mt_grid_w = (bw + MT - 1u) / MT;
uint mt_grid_h = (bh + MT - 1u) / MT;
uint slot_count = mt_grid_w * mt_grid_h * MT * MT;
if (tid >= slot_count) return;
uint2 b = bc_slot_to_block(tid, bw);
if (b.x >= bw || b.y >= bh) return; // padding inside the last macro-tile
half3 rgb[16];
read_rgb_block(src, ushort2(b * 4u), rgb);
output_blocks[tid] = spark_encode_bc7_rgb(rgb, quality);
}I measured the performance of both approaches and compared them with the standard method using a temporary buffer and a blit. I ran each method 100 times on an M4 at quality level 2 and report the best and average times for a 1024×1024 texture:
| method | best | average |
|---|---|---|
| writes_swizzled | 0.020 ms | 0.036 ms |
| reads_swizzled | 0.021 ms | 0.038 ms |
| linear + blit | 0.025 ms | 0.043 ms |
The two swizzled variants are closely tied. On smaller textures writes_swizzled tends to win, on larger textures reads_swizzled pulls ahead, but the difference is negligible either way.
Both outperform the blit approach by around 20%, an improvement that you don’t want to overlook. At quality level 1 the kernel is purely bandwidth limited and the difference is even more pronounced, approximately 28% faster:
| method | best | avg |
|---|---|---|
| writes_swizzled | 0.013 ms | 0.026 ms |
| reads_swizzled | 0.014 ms | 0.026 ms |
| linear + blit | 0.018 ms | 0.036 ms |
On mobile the differences are more muted, but still worthwhile at around 17% improvement.
iPhone 16 (A18):
| method | best | avg |
|---|---|---|
| writes_swizzled | 0.168 ms | 0.257 ms |
| reads_swizzled | 0.170 ms | 0.245 ms |
| linear + blit | 0.201 ms | 0.304 ms |
iPhone 8 (A11):
| method | best | avg |
|---|---|---|
| writes_swizzled | 0.578 ms | 0.606 ms |
| reads_swizzled | 0.573 ms | 0.593 ms |
| linear + blit | 0.689 ms | 0.721 ms |
Despite the benefits, this technique is somewhat risky. There’s no guarantee that future devices will use the same tiling format, in fact, some of the iOS devices I’ve tested use a different Morton ordering.
It’s also interesting to note that in Vulkan, some (most?) vendors disable tiling when writes to compressed textures are enabled, resulting in textures that are in a block-linear format. To avoid that they would have to modify every shader that writes to those textures in order to apply the swizzling, which would require dynamic shader compilation.
When sampled, block-linear textures have worse caching performance than swizzled textures. I haven’t measured the impact, and IHVs have dismissed this concern, but I think it’s worth taking a closer look at this in the future and implementing a similar approach in Vulkan.
The drawback is that you would need slightly different code paths depending on the target device, but hey, that’s why you want to license Spark, rather than rolling your own.
The upcoming Spark SDK will include a Metal example demonstrating this technique in more detail, with support for non-power of two textures, different block-compression formats, and devices as old as iPhone 6 (A8).