In my previous post Writing to Compressed Textures in Metal, I showed how Metal heaps can be used to alias buffers and textures to inspect their actual memory layout. Something that caught my attention was how much memory is wasted with non-power-of-two textures. On many devices the texture dimensions get rounded up to the next power of two, and you end up paying for padding memory you never use.
You may think that non power of two textures do not have much use outside of render targets, but it turns out that they are much more prevalent than what most people realize. When allocating ASTC textures with power-of-two pixel dimensions the resulting textures often have non-power-of-two block dimensions, and it’s the block dimensions, not the pixel dimensions, that determine how much memory the texture occupies.
How bad is it in practice? I ran a test on several mobile devices to find out. In the tables below I compared the nominal bpp, that is, the exact memory footprint with no alignment padding, against the actual bpp considering the alignment.
Early Apple and all PowerVR GPUs
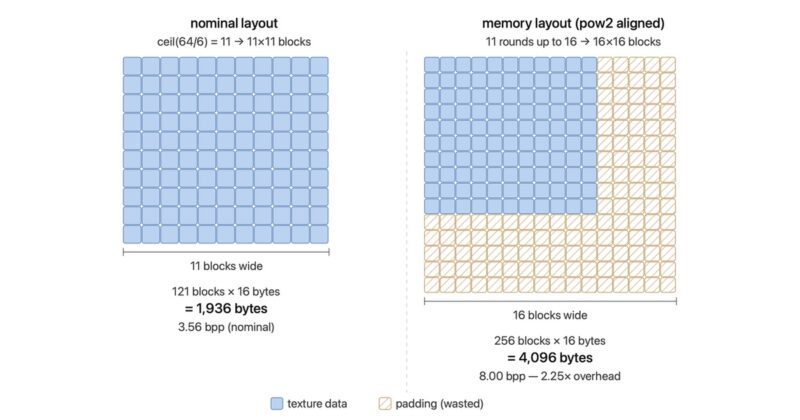
Early Apple GPUs and all current PowerVR GPUs are the worst offenders, block dimensions are simply aligned to the next power of two, ie following the following pseudocode:
bw = (w + block_size.x - 1) / block_size.x
bh = (h + block_size.y - 1) / block_size.y
size = 16 * nextPow2(bw) * nextPow2(bh)
bpp = 8 * size / (w * h)| block | nominal | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|---|
| 4×4 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 5×4 | 6.40 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 5×5 | 5.12 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 6×5 | 4.27 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 6×6 | 3.56 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 8×5 | 3.20 | 4.00 | 4.00 | 4.00 | 4.00 | 4.00 | 4.00 |
| 8×6 | 2.67 | 4.00 | 4.00 | 4.00 | 4.00 | 4.00 | 4.00 |
| 10×5 | 2.56 | 4.00 | 4.00 | 4.00 | 4.00 | 4.00 | 4.00 |
| 10×6 | 2.13 | 4.00 | 4.00 | 4.00 | 4.00 | 4.00 | 4.00 |
| 8×8 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 10×8 | 1.60 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 10×10 | 1.28 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 12×10 | 1.07 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 12×12 | 0.89 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
The result collapses all ASTC block sizes into just three memory footprint categories: 8, 4, and 2 bpp, regardless of the block size chosen.
PowerVR matching early Apple behavior isn’t surprising, the two share common architectural roots. That said, given how long ASTC has been the dominant mobile compression format, it’s disappointing to see this inefficiency persist in current PowerVR hardware.
Modern Apple GPUs
Modern Apple GPUs reduce waste by aligning block dimensions to a 32-block macro tile boundary rather than the next power of two. For block counts smaller than 32, where the next power of two is the tighter bound, it falls back to power-of-two alignment automatically, since min(nextPow2(n), align32(n)) picks whichever is smaller:
bw = (w + block_size.x - 1) / block_size.x
bh = (h + block_size.y - 1) / block_size.y
size = 16 * min(nextPow2(bw), align32(bw)) * min(nextPow2(bh), align32(bh))
bpp = 8 * size / (w * h)| block | nominal | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|---|
| 4×4 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 5×4 | 6.40 | 8.00 | 8.00 | 8.00 | 8.00 | 7.00 | 6.50 |
| 5×5 | 5.12 | 8.00 | 8.00 | 8.00 | 8.00 | 6.12 | 5.28 |
| 6×5 | 4.27 | 8.00 | 8.00 | 8.00 | 6.00 | 5.25 | 4.47 |
| 6×6 | 3.56 | 8.00 | 8.00 | 8.00 | 4.50 | 4.50 | 3.78 |
| 8×5 | 3.20 | 4.00 | 4.00 | 4.00 | 4.00 | 3.50 | 3.25 |
| 8×6 | 2.67 | 4.00 | 4.00 | 4.00 | 3.00 | 3.00 | 2.75 |
| 10×5 | 2.56 | 4.00 | 4.00 | 4.00 | 4.00 | 3.50 | 2.84 |
| 10×6 | 2.13 | 4.00 | 4.00 | 4.00 | 3.00 | 3.00 | 2.41 |
| 8×8 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 10×8 | 1.60 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 1.75 |
| 10×10 | 1.28 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 1.53 |
| 12×10 | 1.07 | 2.00 | 2.00 | 2.00 | 2.00 | 1.50 | 1.31 |
| 12×12 | 0.89 | 2.00 | 2.00 | 2.00 | 2.00 | 1.12 | 1.12 |
Adreno 740
Adreno 740 uses a smaller 16-block tile size than Apple’s 32-block alignment, but with an important difference: only the block width (stride) is aligned, while the height is left exact. This asymmetry avoids padding an entire dimension unnecessarily, reducing waste compared to a fully 2D-aligned scheme:
bw = (w + block_size.x - 1) / block_size.x
bh = (h + block_size.y - 1) / block_size.y
size = 16 * align16(bw) * bh
bpp = 8 * size / (w * h)| block | nominal | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|---|
| 4×4 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 5×4 | 6.40 | 8.00 | 8.00 | 8.00 | 7.00 | 6.50 | 6.50 |
| 5×5 | 5.12 | 8.00 | 8.00 | 8.00 | 6.12 | 5.28 | 5.28 |
| 6×5 | 4.27 | 8.00 | 8.00 | 6.00 | 5.25 | 4.47 | 4.47 |
| 6×6 | 3.56 | 8.00 | 8.00 | 4.50 | 4.50 | 3.78 | 3.78 |
| 8×5 | 3.20 | 8.00 | 4.00 | 4.00 | 3.50 | 3.25 | 3.25 |
| 8×6 | 2.67 | 8.00 | 4.00 | 3.00 | 3.00 | 2.75 | 2.75 |
| 10×5 | 2.56 | 8.00 | 4.00 | 4.00 | 3.50 | 2.84 | 2.64 |
| 10×6 | 2.13 | 8.00 | 4.00 | 3.00 | 3.00 | 2.41 | 2.23 |
| 8×8 | 2.00 | 8.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 10×8 | 1.60 | 8.00 | 2.00 | 2.00 | 2.00 | 1.75 | 1.62 |
| 10×10 | 1.28 | 8.00 | 2.00 | 2.00 | 2.00 | 1.53 | 1.32 |
| 12×10 | 1.07 | 8.00 | 2.00 | 2.00 | 1.50 | 1.31 | 1.12 |
| 12×12 | 0.89 | 8.00 | 2.00 | 2.00 | 1.12 | 1.12 | 0.95 |
Adreno 640
Interestingly, Adreno 640 uses a finer 4-block alignment than Adreno 740’s 16-block alignment, which translates to noticeably smaller allocations, particularly for small textures where coarse alignment wastes a larger fraction of the total footprint. Like Adreno 740, only the block width is aligned:
bw = (w + block_size.x - 1) / block_size.x
bh = (h + block_size.y - 1) / block_size.y
size = 16 * align4(bw) * bh
bpp = 8 * size / (w * h)| block | nominal | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|---|
| 4×4 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 5×4 | 6.40 | 8.00 | 7.00 | 6.50 | 6.50 | 6.50 | 6.44 |
| 5×5 | 5.12 | 6.50 | 5.69 | 5.28 | 5.23 | 5.21 | 5.16 |
| 6×5 | 4.27 | 4.88 | 4.88 | 4.47 | 4.43 | 4.30 | 4.30 |
| 6×6 | 3.56 | 4.12 | 4.12 | 3.70 | 3.70 | 3.59 | 3.59 |
| 8×5 | 3.20 | 3.25 | 3.25 | 3.25 | 3.22 | 3.20 | 3.20 |
| 8×6 | 2.67 | 2.75 | 2.75 | 2.69 | 2.69 | 2.67 | 2.67 |
| 10×5 | 2.56 | 3.25 | 3.25 | 2.84 | 2.62 | 2.60 | 2.60 |
| 10×6 | 2.13 | 2.75 | 2.75 | 2.35 | 2.18 | 2.17 | 2.17 |
| 8×8 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 10×8 | 1.60 | 2.00 | 2.00 | 1.75 | 1.62 | 1.62 | 1.62 |
| 10×10 | 1.28 | 1.75 | 1.62 | 1.42 | 1.32 | 1.31 | 1.30 |
| 12×10 | 1.07 | 1.75 | 1.22 | 1.22 | 1.12 | 1.11 | 1.08 |
| 12×12 | 0.89 | 1.50 | 1.03 | 1.03 | 0.92 | 0.92 | 0.90 |
Adreno 540 & Mali
Adreno 540 shares the same 4-block alignment as Adreno 640, but applies it to both width and height rather than width alone. Mali Bifrost and Valhall happen to use the identical scheme, arriving at the same formula from a different architecture entirely. I haven’t been able to test on Midgard, so it’s unclear whether that holds for older Mali hardware as well.
bw = (w + block_size.x - 1) / block_size.x
bh = (h + block_size.y - 1) / block_size.y
size = 16 * align4(bw) * align4(bh)
bpp = 8 * size / (w * h)| block | nominal | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|---|
| 4×4 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 5×4 | 6.40 | 8.00 | 7.00 | 6.50 | 6.50 | 6.50 | 6.44 |
| 5×5 | 5.12 | 8.00 | 6.12 | 5.28 | 5.28 | 5.28 | 5.18 |
| 6×5 | 4.27 | 6.00 | 5.25 | 4.47 | 4.47 | 4.37 | 4.33 |
| 6×6 | 3.56 | 4.50 | 4.50 | 3.78 | 3.78 | 3.61 | 3.61 |
| 8×5 | 3.20 | 4.00 | 3.50 | 3.25 | 3.25 | 3.25 | 3.22 |
| 8×6 | 2.67 | 3.00 | 3.00 | 2.75 | 2.75 | 2.69 | 2.69 |
| 10×5 | 2.56 | 4.00 | 3.50 | 2.84 | 2.64 | 2.64 | 2.62 |
| 10×6 | 2.13 | 3.00 | 3.00 | 2.41 | 2.23 | 2.18 | 2.18 |
| 8×8 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 10×8 | 1.60 | 2.00 | 2.00 | 1.75 | 1.62 | 1.62 | 1.62 |
| 10×10 | 1.28 | 2.00 | 2.00 | 1.53 | 1.32 | 1.32 | 1.32 |
| 12×10 | 1.07 | 2.00 | 1.50 | 1.31 | 1.12 | 1.12 | 1.09 |
| 12×12 | 0.89 | 2.00 | 1.12 | 1.12 | 0.95 | 0.95 | 0.90 |
Samsung Xclipse
The Xclipse results don’t fit a clean formula. At small texture sizes the behavior roughly matches Adreno 740’s 16-block alignment, but at larger sizes the results become less efficient and notably non-monotonic. A texture can occupy more with a larger block, than with a smaller block. Further investigation with additional texture sizes is needed to figure out the exact allocation scheme.
| block | nominal | 64 | 128 | 256 | 512 | 1024 | 2048 |
|---|---|---|---|---|---|---|---|
| 4×4 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 |
| 5×4 | 6.40 | 8.00 | 8.00 | 8.00 | 8.00 | 8.00 | 7.00 |
| 5×5 | 5.12 | 8.00 | 8.00 | 8.00 | 8.00 | 5.28 | 6.12 |
| 6×5 | 4.27 | 8.00 | 8.00 | 8.00 | 5.25 | 6.00 | 5.25 |
| 6×6 | 3.56 | 8.00 | 8.00 | 4.50 | 4.50 | 4.50 | 4.50 |
| 8×5 | 3.20 | 8.00 | 4.00 | 4.00 | 4.00 | 4.00 | 3.50 |
| 8×6 | 2.67 | 8.00 | 4.00 | 3.00 | 4.00 | 3.00 | 3.00 |
| 10×5 | 2.56 | 8.00 | 4.00 | 4.00 | 4.00 | 4.00 | 3.50 |
| 10×6 | 2.13 | 8.00 | 4.00 | 3.00 | 4.00 | 3.00 | 3.00 |
| 8×8 | 2.00 | 8.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 10×8 | 1.60 | 8.00 | 2.00 | 2.00 | 2.00 | 2.00 | 2.00 |
| 10×10 | 1.28 | 8.00 | 2.00 | 2.00 | 2.00 | 2.00 | 1.32 |
| 12×10 | 1.07 | 8.00 | 2.00 | 2.00 | 2.00 | 1.31 | 1.50 |
| 12×12 | 0.89 | 8.00 | 2.00 | 2.00 | 1.12 | 1.12 | 1.12 |
Conclusions
The takeaway for asset pipelines is that nominal bpp is a poor predictor of actual memory usage, especially on older hardware or at small texture sizes.
It’s worth keeping in mind that texture compression serves two distinct goals: reducing memory footprint and reducing bandwidth. Bandwidth savings are proportional to the nominal bpp regardless of alignment. A 6×6 block will always fetch less data per texel than a 4×4 block during sampling. Memory footprint, however, is affected by alignment, and that’s where the different hardware behaviors described in this article matters.
For example, on early Apple and PowerVR hardware, switching from 4×4 to 6×6 ASTC cuts bandwidth by more than half, but saves no memory at all for small power-of-two textures.
The following table summarizes the actual bpp for each GPU family at two representative block and texture sizes. The overhead varies significantly across GPU families, from a 2.5× penalty on early Apple and PowerVR hardware down to near-nominal on Adreno 640 and Mali.
| GPU family | 6×6 @ 512 | 10×6 @ 1024 | formula |
|---|---|---|---|
| Early Apple / PowerVR | 8.00 | 4.00 | pow2 both axes |
| Modern Apple | 4.50 | 3.00 | min(pow2, align32) both axes |
| Adreno 740 | 4.50 | 2.41 | align16 width only |
| Mali / Adreno 540 | 3.78 | 2.18 | align4 both axes |
| Adreno 640 | 3.70 | 2.17 | align4 width only |